How to detect, prevent, and mitigate buffer overflow attacks
Mar 31, 2024 | 8 min read

Subscribe
In the late 1980s, a buffer overflow in UNIX’s fingerd program allowed Robert T. Morris to create a worm which infected 10% of the Internet—in two days. This event launched cybersecurity to the forefront of computer science headlines for one of the first times in history.
Nearly three decades later in 2014, a buffer overflow vulnerability in the OpenSSL cryptography library was disclosed to the public. This flaw became known as “Heartbleed.” It exposed hundreds of millions of users of popular online services and software platforms to a vulnerable version of the OpenSSL software.
More recently, we've seen the curl and libcurl vulnerabilities make headlines, as the newest buffer overflow vulnerabilities.
Impeding the next Heartbleed or Morris Worm first requires an understanding of buffer overflows and how to detect them. Next, it’s important to understand the process and consequences associated with a successful overrun exploitation. Only once these are in place can a plan for buffer overflow prevention and mitigation be put into place.
What is buffer overflow?
Before seeking out buffer overflows in code, let’s take a look at what they are in the first place. As the name implies, a buffer overflow is a type of vulnerability that deals with buffers, or memory allocations in languages that offer direct, low-level access to read and write memory. In the simplest terms, it is when a buffer's storage capacity is exceeded by a to-large quantity of data.
In the case of languages such as C and Assembly, reading from or writing to one of these allocations does not entail any automatic bounds checking. In other words, there is no check that the number of bytes to be written or read will actually fit in the buffer in question. Thus, the program can “overflow” the capacity of the buffer. This results in data being written past its end and overwriting the contents of subsequent addresses on the stack or heap, or extra data being read. In fact, the latter is exactly what happened in the case of the Heartbleed bug.
How to detect buffer overflow
With this definition in mind, we can explore how to detect these flaws. When working with source code, the short answer to buffer overflows is just to pay special attention to where buffers are used, modified, and accessed. Of particular note would be functions dealing with input supplied by a user or other outside source, as these would provide the easiest vector for exploitation of the overflow. For example, when asking a user a yes or no question, it seems feasible to store the user’s string input in a small buffer—only large enough for the string “yes” as the following example shows:

Looking at the code, it is clear that no bounds checking is performed. If the user enters “maybe” then the program will likely stop working rather than asking the user for a valid answer and re-prompting with the question. The user’s answer is simply written into the buffer, regardless of its length.
In this example, since user_answer is the only variable declared, the next values on the stack would be the return address value, or the location in memory to which the program will return after running the askQuestion function. This means that if the user enters four bytes of data (enough to fill the memory specifically set aside for the buffer), followed by a valid address in memory, the program’s return address will be modified. This allows the user to force the program to exit the function at a different point in the code than originally intended, potentially causing the program to behave in dangerous and unintended ways.
If the first step to detect buffer overflows in source code is understanding how they work, and the second step is knowing to look for external input and buffer manipulations, then the third step is to know what functions are susceptible to this vulnerability and can act as red flags for its presence. As illustrated above, the gets function is perfectly happy writing past the bounds of the buffer provided to it. In fact, this quality extends to the whole family of related functions (including strcopy, strcat, and printf/sprint). Anywhere one of these functions is used, there is likely to be a buffer overflow vulnerability.
How to prevent buffer overflow
The ability to detect buffer overflow vulnerabilities in source code is certainly valuable. However, eliminating them from a code base requires consistent detection as well as a familiarity with secure practices for buffer handling. The easiest way to prevent these vulnerabilities is to simply use a language that does not allow for them. C allows these vulnerabilities through direct access to memory and a lack of strong object typing. Languages that do not share these aspects are typically immune. Java, Python, and .NET, among other languages and platforms, don’t require special checks or changes to mitigate overflow vulnerabilities.
Completely changing the language of development is not always possible, of course. When this is the case, use secure practices for handling buffers. In the case of string handling functions, there has been a great deal of discussion on what methods are available, which ones are safe to use, and which to avoid. The strcopy and strcat functions copy a string into a buffer and append the contents of one buffer onto another, respectively. These two exhibit the unsafe behavior of not checking any bounds on the target buffer, and will write past the buffer’s limits if given enough bytes to do so.
One commonly suggested alternative to these are their associated strn- versions. These versions only write to the maximum size of the target buffer. At a glance this sounds like the ideal solution. Unfortunately, there is a small nuance with these functions that can still cause problems. Upon reaching the buffer limit, if a terminating character isn’t placed in the last byte of the buffer, major problems can occur when the buffer is then read:

In this simplified example, we see the dangers of non-null-terminated strings. When “foo” is placed into normal_buffer, it is null terminated because there is additional space in the buffer. That is not the case with full_buffer. When this is executed, the results look like this:

The value in normal_buffer has printed correctly, but full_buffer printed an extra character. This is somewhat of a best case scenario. Had the next bytes in the stack been another character buffer or other printable string, the print function would have continued reading until that string’s terminating character was reached.
The bad news is that C does not provide a standard, secure alternative to these functions. The good news is that there are several platform-specific implementations available. OpenBSD provides strlcpy and strlcat, which work similarly to the strn- functions, except they truncate the string one character early to make room for a null terminator. Likewise, Microsoft provides its own secure implementations of commonly misused string handling functions: strcpy_s, strcat_s, and sprintf_s. Below is a table containing safer alternatives to best-avoided functions:
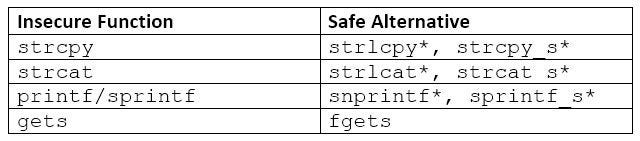
*Asterisks denote functions that are not part of C Standard Libraries.
The use of the secure alternatives listed above are preferable. When that is not possible, it is necessary to perform manual bounds checking and null termination when handling string buffers.
How to mitigate buffer overflow
In the event that an unsafe function leaves an open overflow opportunity, all is not lost. Advances are being made to help detect these vulnerabilities at compile and runtime. When running a program, compilers often create random values known as canaries, and place them on the stack after each buffer. Much like the coalmine birds for which they are named, these canary values flag danger. Checking the value of the canary against its original value can determine whether a buffer overflow has occurred. If the value has been modified, the program can be shut down or go into an error state rather than continuing to the potentially modified return address.
Additional defenses are provided by some of today’s operating systems in the form of non-executable stacks and address space layout randomization (ASLR). Non-executable stacks (i.e., data execution prevention [DEP]) mark the stack and in some cases other structures as areas where code cannot be executed. This means that an attacker cannot inject exploit code onto the stack and expect it to successfully run.
ASLR was developed to defend against return oriented programming (a workaround to non-executable stacks where existing pieces of code are chained together based on the offsets of their addresses in memory). It works by randomizing the memory locations of structures so that their offsets are harder to determine. Had these defenses existed in the late 1980s, the Morris Worm may have been prevented. This is due to the fact that it functioned in part by filling a buffer in the UNIX fingerd protocol with exploit code, then overflowing that buffer to modify the return address to point to the buffer filled with exploit code. ASLR and DEP would have made it more difficult to pinpoint the address to point to, if not making that area of memory non-executable completely.
Sometimes a vulnerability slips through the cracks, remaining open to attack despite controls in place at the development, compiler, or operating system level. Sometimes, the first indication that a buffer overflow is present can be a successful exploitation. In this situation, there are two critical tasks to accomplish. First, the vulnerability needs to be identified, and the code base must be changed to resolve the issue. Second, the goal becomes to ensure that all vulnerable versions of the code are replaced by the new, patched version. Ideally this will start with an automatic update that reaches all Internet-connected systems running the software.
However, it cannot be assumed that such an update will provide sufficient coverage. Organizations or individuals may use the software on systems with limited access to the Internet. These cases require manual updates. This means that news of the update needs to be distributed to any admins who may be using the software, and the patch must be made easily available for download. Patch creation and distribution should occur as close to the discovery of the vulnerability as possible. Thus, minimizing the amount of time users and systems are vulnerable.
Through the use of safe buffer handling functions, and appropriate security features of the compiler and operating system, a solid defense against buffer overflows can be built. Even with these steps in place, consistent identification of these flaws is a crucial step to preventing an exploit. Combing through lines of source code looking for potential buffer overflows can be tedious. Additionally, there is always the possibility that human eyes may miss on occasion. Luckily, static analysis tools (similar to linters) that are used to enforce code quality have been developed specifically for the detection of security vulnerabilities during development.
How we can help
Black Duck® Security Advisories provide customers with in-depth analysis of vulnerabilities in open source products, combining a range of available information with regular reviewing and monitoring to ensure accurate coverage. These advisories contain the details necessary to understand, prioritize, and remediate vulnerabilities within the context of your applications, and they’re normally published well in advance of the corresponding CVE analysis, if a CVE ID has been allocated.
-This blog was reviewed by Mike McGuire.
Learn more about Black Duck Security Advisories

Continue Reading

Leading organizations address growing regulatory pressures with automation

Apr 28, 2026 | 1 min read

Decoding AI-enabled dev: Top concerns, hidden benefits, and smart investment strategies

Mar 31, 2026 | 4 min read

Navigating the AI frontier: Risks, benefits, and uncharted territory in code development
Jan 22, 2026 | 3 min read